Обработка XML и загрузка данных из него
Задача
Обработать имеющийся файл формата XML, разобрать данные по структуре для дальнейшего использования (например, вставки и обновления строк Колибри).
Исходные данные
Перед тем как приступить к решению задачи, ознакомимся с имеющимся файлом bookstore.xml. На его основе необходимо составить хранилище книжного магазина.
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book title="Everyday Italian">
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book title="Harry Potter">
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book title="XQuery Kick Start">
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book>
<book title="Learning XML">
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
Сценарий решения задачи
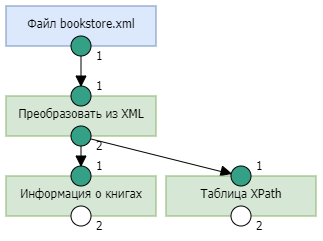
Решение задачи будет заключаться в создании процесса, который будет включать следующие шаги:
- Получение XML файла.
- Преобразование файла в XML.
- Получение данных о книгах с помощью узла "Таблица XPath".
- Получение данных об авторах книг с помощью узла "Таблица XPath".
- Присоединение к данным о книгах данных об их авторах.
Используемые узлы
Прочитать файл
Преобразовать из XML
Таблица XPath
Присоединение
Построение и настройка процесса
- Создадим и сохраним новый процесс.
- Для обработки файла процессом добавим узел Прочитать файл.
Укажем название узла "Файл bookstore.xml" и настроим свойства, указав сетевой путь до файла XML.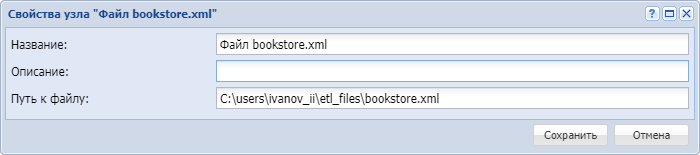
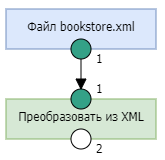
- Для преобразования выходных данных узла "Файл bookstore.xml"* из потока байт в формат XML добавим узел Преобразовать из XML и соединим его входной порт с выходным портом узла "Файл bookstore.xml".
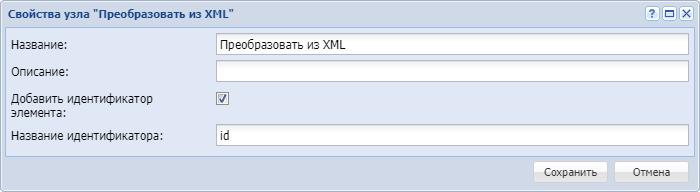
- Заполним свойства узла Преобразовать из XML, установив свойство "Добавить идентификатор элемента", чтобы далее иметь возможность установить связи между родительским и дочерними элементами.
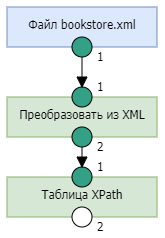
- Для обработки полученного XML-документа добавим в процесс узел Таблица XPath и соединим его входной порт с выходным портом узла Преобразовать из XML". .
У узла Таблица XPath укажем название "Информация о книгах" и заполним свойства для получения данных.
Укажем//bookкак корневой элемент для того, чтобы получить в качестве строк выходной таблицы все элементыbook.
Файл содержит информацию одного книжного магазина, поэтому определение родительского элемента для элементовbookне требуется, свойство "Добавить идентификатор родительского элемента" не устанавливаем.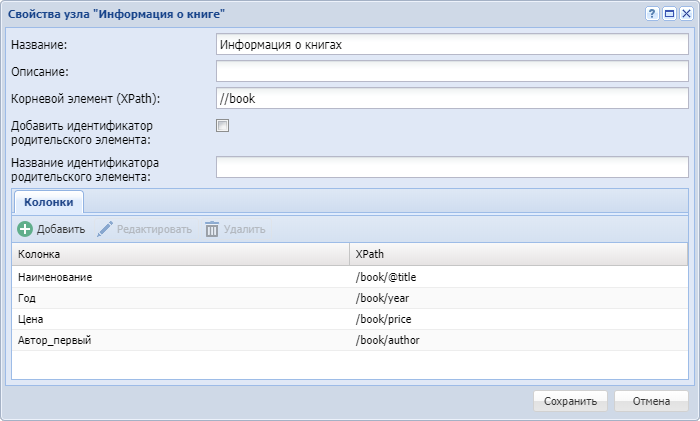
Для получения данных о книгах добавим колонки и укажем соответствующий XPath.
Колонка XPath Примечание Наименование /book/@titleПолучим атрибут titleэлементаbookГод /book/yearПолучим элемент yearпотомок элементаbookЦена /book/priceПолучим элемент priceпотомок элементаbookАвтор /book/authorПолучим один из множества элементов authorпотомка элементаbook.
Получение полного перечня авторов будет выполнено отдельным узловВыполним проверку процесса, при наличии ошибок исправим их.
- Запустим процесс в отладке для просмотра результатов узла "Информация о книгах".
Обрабатываемый XML-документ содержал 4 элементаbook, которые преобразованы в строки выходной таблицы.
Колонкаidдобавлена в выходную таблицу, так как в узле Преобразовать из XML было установлено свойство "Добавить идентификатор элемента".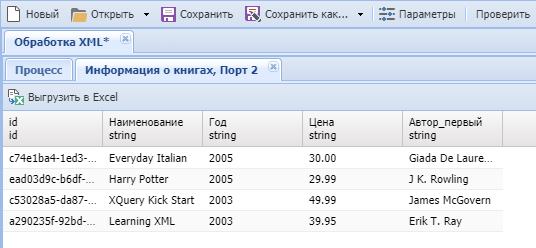
- Для получения полного перечня авторов добавим в процесс ещё один узел Таблица XPath и соединим его входной порт с выходным портом узла "Преобразовать из XML".
- У узла Таблица XPath укажем название "Информация об авторах" и заполним свойства для получения данных.
Укажем//book/authorкак корневой элемент для того, чтобы получить в качестве строк выходной таблицы все элементыauthorродительских элементовbook.
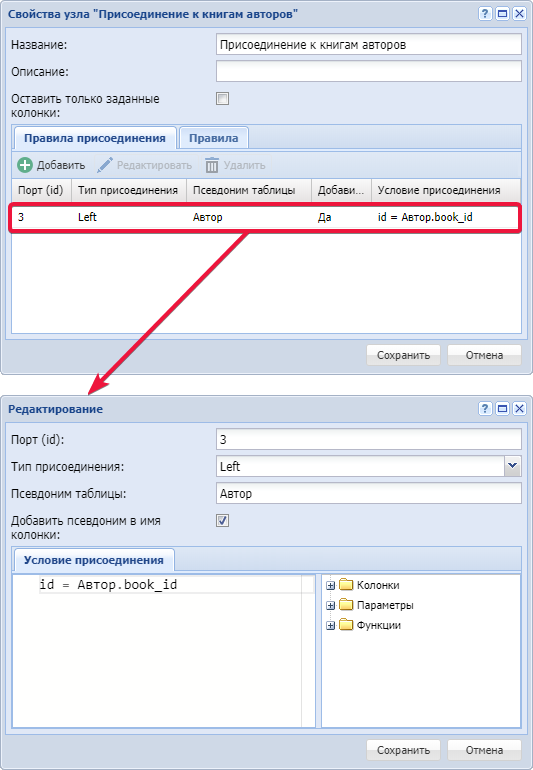
Установим ✓ в свойстве "Добавить идентификатор родительского элемента", для добавления элементамauthorидентификатора родительского элементаbook_id, это позволит позже присоединить элементыauthorк элементамbook.
Для получения значений элементовauthorдобавим соответствующую колонку.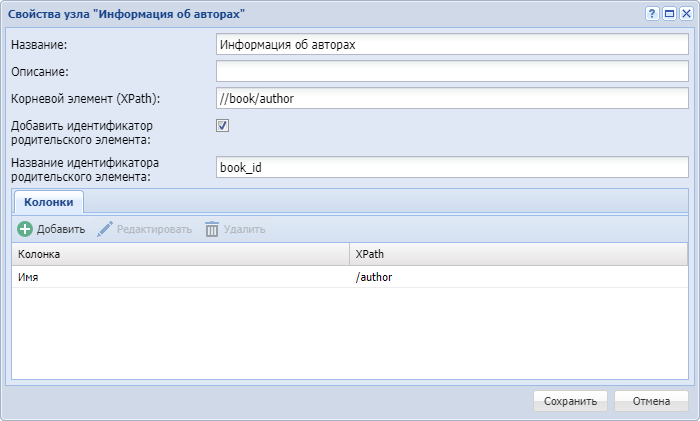
- Запустим процесс в отладке для просмотра результатов узла "Информация о авторах".
Обрабатываемый XML-документ содержал 8 элементовauthor, которые преобразованы в строки выходной таблицы.
Колонкаbook_idдобавлена в выходную таблицу, и позволит присоединить данные к выходным данным узла "Информация о книгах".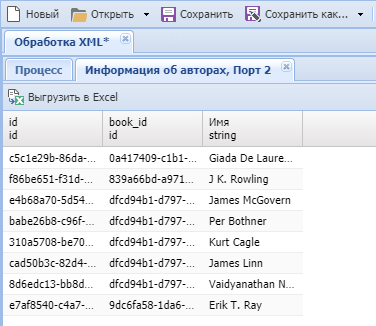
- Для присоединения к данным о книгах данных об их авторах добавим в процесс узел Присоединение и соединим его с выходными портами узлов "Информация о книгах" и "Информация об авторах".
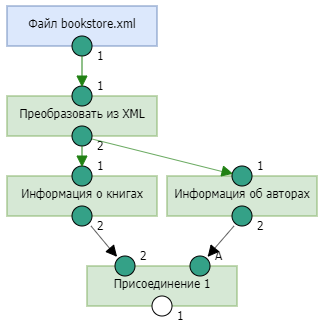
- У узла Присоединение укажем название "Присоединение к книгам авторов", заполним свойства и отредактируем правило присоединения.
- Запустим процесс в отладке для просмотра результатов узла "Присоединение к книгам авторов".
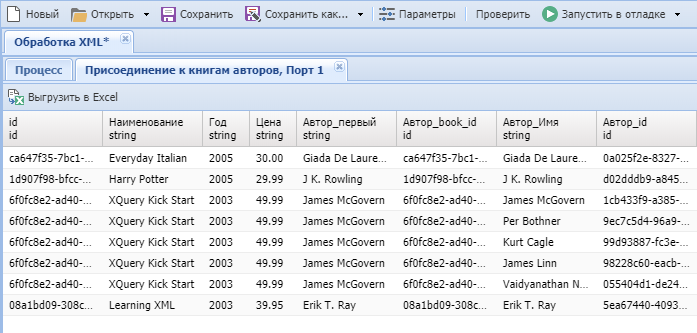
- Далее таблица с данными, полученная из узла "Присоединение к книгам авторов", может быть обработана с помощью других узлов, а данные записаны в хранилище.